
In a previous post, we dealt about ‘Under-replicated blocks in the HDFS‘. However, while decommissioning a couple of worker nodes, I also noticed there were some blocks with no live replicas. That would mean, if a datanode is ‘deleted’ the file with these blocks will get corrupted.
Letting the node(s) to decommission make take sweet long time which may not be ideal situation for everyone, given we are paying by the hour in cloud!
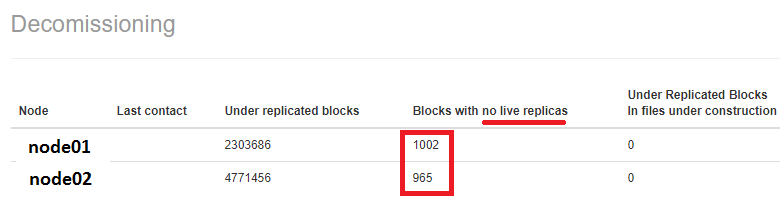
There are two methods to deal with this issue.
- The forceful method would be to switch between the namenodes. This replicates some of the blocks during the switch. While this may seem to be fastest way, it may not be possible for multiple switches on a production environment.
- The graceful method would be to use ‘metasave’ option from -dfsadmin commands and deal with the blocks, one by one. Sample code is presented below.
rm /tmp/single_replica
hdfs dfsadmin -metasave metasave-report.txt
cat /path/to/logs/hadoop/hdfs/metasave-report.txt | grep "l: 1" | cut -d':' -f1 >> /tmp/single_replica
for hdfsfile in `cat /tmp/single_replica`; do hadoop fs -setrep 3 $hdfsfile; done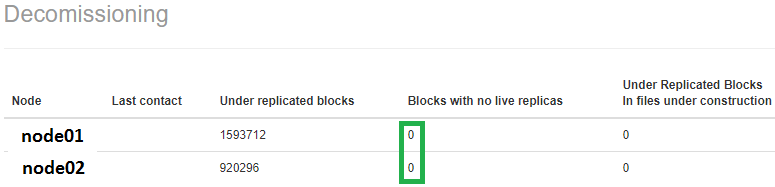

I think you also need to grep for 0 live replicas (l) in the metasave-report.txt. For me, this turned out to be lot quicker.
cat /path/to/logs/hadoop/hdfs/metasave-report.txt | grep “l: 0|l: 1” | cut -d’:’ -f1 >> /tmp/single_replica
LikeLiked by 1 person