
Working on a project to implement LLM in Databricks using Hugging face, I faced issue of being unable to download … More

Working on a project to implement LLM in Databricks using Hugging face, I faced issue of being unable to download … More

How to deal with the requirement to order a DataFrame using more than one column simultaneously? Also, consider some values … More
For a given dataframe, with multiple occurrence of a particular column value, one may desire to retain only one (or … More
While working with PySpark, I came across a requirement, where data in a column had to be split using delimiters … More
As a Data Engineer, one faces the need to share files securely over the internet. An easy way of doing … More
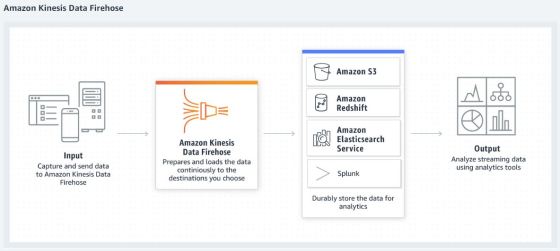
Text data analysis is a staple use case for the Data Analytics world! There are multiple firms which enable capture … More
