
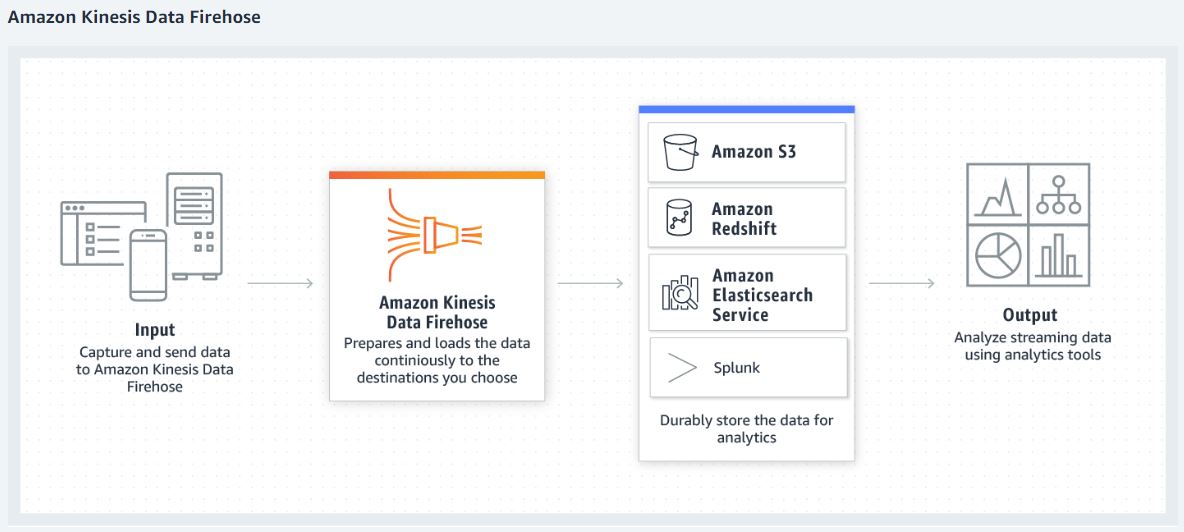
Text data analysis is a staple use case for the Data Analytics world! There are multiple firms which enable capture of various data points and enable availability of such data logs to businesses seeking to better understand their consumer behavior.
Examples of such pipelines like Twitter Data processing pipeline using AWS Kinesis set up on Kubernetes are available over the web.
In this blog, I would like to document my experiences with optimizing pipeline using Amazon Kinesis Firehose. While data collection applications like Apache Kafka, Apache NiFi etc. are the ‘swiss knife’ of Data Analytics World, AWS Kinesis is a managed service which simplifies this demo.
So! Let’s dive in. I am including screenshots for the configurations I manipulated.


We are able to create S3 bucket as an endpoint, on the fly; and also create and select relevant IAM roles for this purpose without stepping out of the Kinesis Firehose set up UI.

Now, we get to the interesting part!
Firehose would buffer incoming records before delivering them to the S3 bucket. Buffer limits are specified by the user, but the lower of the two limits (size or time) is acted upon by Firehose. Firehose also provides options for compression and encryption.
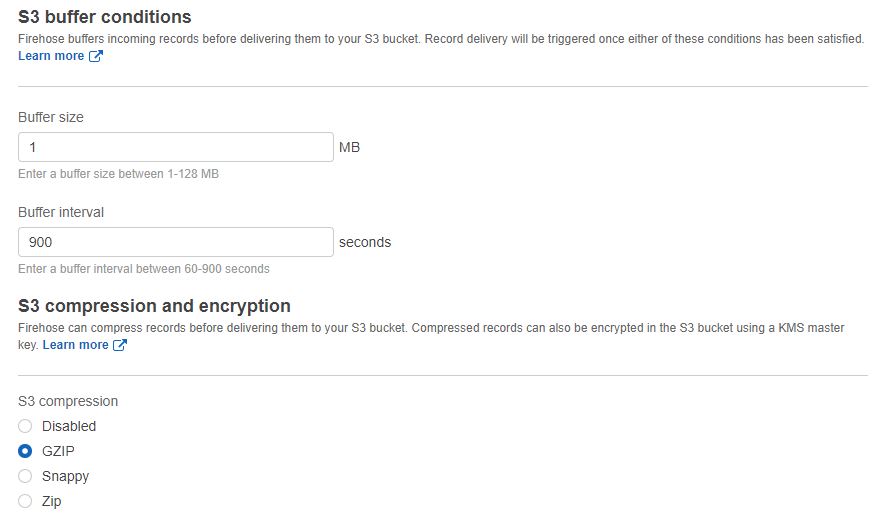
NOTE: Firehose would compress after the input data hits the 'buffer' limits.
10MB buffer size, does not necessarily mean 10 MB compressed file!
Kinesis Firehose makes it really easy and simple to test your flow with ‘demo data‘ and also monitor various data points related to input and output data.

I tried to play around with different Buffer Size, Buffer Time and Compression values to see how the output file comes together in the S3 bucket.
| Buffer Size | Buffer Time | Compression | Output file size on S3 |
| 5 MB | 300 s | – | 2.4 MB |
| 1 MB | 900 s | Gzip | 163.0 KB |
| 5 MB | 900 s | GZip | 762.1 KB |
| 10 MB | 900 s | GZip | 1.1 MB |
| 5 MB | 900 s | Snappy | 1.4 MB |
| 5 MB | 900 s | Zip | 761.1 KB |
| 5 MB | 900 s | – | 5.0 MB |

So, based on my demo and if needed, further testing with actual data, it will be easy to estimate the behavior of data flowing in and to the output bucket. Questions that can be easily answered by looking at this demo:
How to concatenate S3 files when using AWS Firehose?
What is the best zip compression level for JSON or text files?
